2026
Understanding and Supporting Online Discussion with Opinionated Chatbots
Tianqi Song, Chi-Lan Yang, Zihan Liu, Zhengtao Xu, Yibin Feng, Yi-Chieh Lee
ACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW 26)
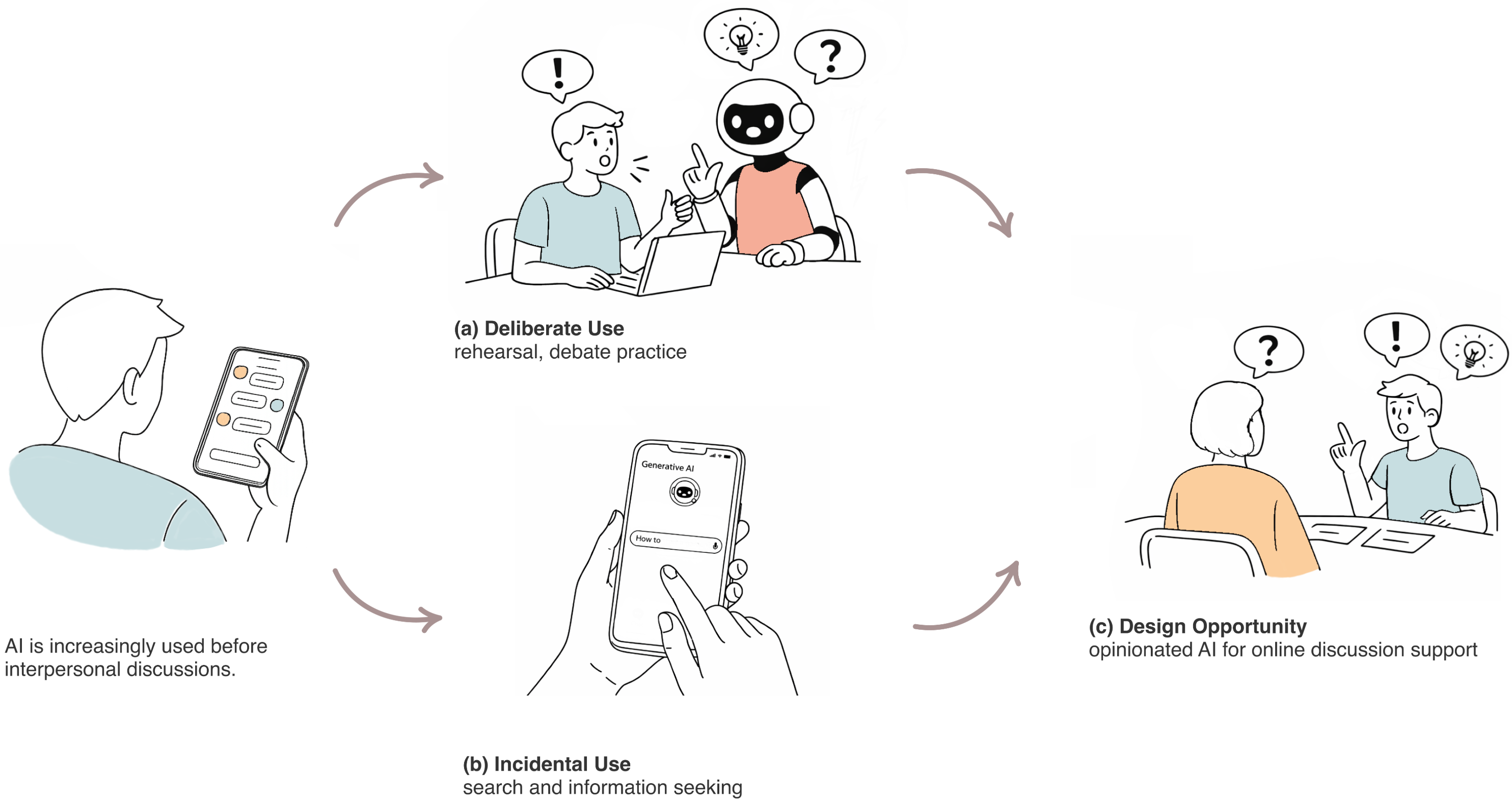
Opinionated chatbots are increasingly present on online platforms and have the potential to shape public discourse by influencing individuals' viewpoints before they engage in discussions. Despite their growing presence, the impact of interacting with opinionated chatbots on subsequent online interactions remains largely unexplored. This study investigated how exposure to different types of opinionated chatbots, specifically those expressing opposing, reinforcing, or balanced viewpoints, affected participants' subsequent online discussions. In a controlled experiment with 83 participants, we found that interacting with an opinionated chatbot that consistently opposed participants' arguments led to greater shifts in opinion, indicating enhanced openness to revising one's initial stance. Conversely, participants who interacted with a chatbot that consistently reinforced their views were more likely to adopt more agreeable communication styles in subsequent conversations with others. Furthermore, interactions with different types of opinionated chatbots resulted in varying levels of trust, as well as different perceptions of chatbots and human interlocutors. Our findings indicate that opinionated chatbots can influence both individuals' opinions on social topics and their communication behaviors in online environments. This presents a trade-off for future designers seeking to facilitate cognitive flexibility in changing opinions while maintaining positive user experiences and trust in the chatbots during public discourse. We discuss the implications for designing opinionated chatbots to promote more constructive and less polarized online discussions.
Understanding and Supporting Online Discussion with Opinionated Chatbots
Tianqi Song, Chi-Lan Yang, Zihan Liu, Zhengtao Xu, Yibin Feng, Yi-Chieh Lee
ACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW 26)
Opinionated chatbots are increasingly present on online platforms and have the potential to shape public discourse by influencing individuals' viewpoints before they engage in discussions. Despite their growing presence, the impact of interacting with opinionated chatbots on subsequent online interactions remains largely unexplored. This study investigated how exposure to different types of opinionated chatbots, specifically those expressing opposing, reinforcing, or balanced viewpoints, affected participants' subsequent online discussions. In a controlled experiment with 83 participants, we found that interacting with an opinionated chatbot that consistently opposed participants' arguments led to greater shifts in opinion, indicating enhanced openness to revising one's initial stance. Conversely, participants who interacted with a chatbot that consistently reinforced their views were more likely to adopt more agreeable communication styles in subsequent conversations with others. Furthermore, interactions with different types of opinionated chatbots resulted in varying levels of trust, as well as different perceptions of chatbots and human interlocutors. Our findings indicate that opinionated chatbots can influence both individuals' opinions on social topics and their communication behaviors in online environments. This presents a trade-off for future designers seeking to facilitate cognitive flexibility in changing opinions while maintaining positive user experiences and trust in the chatbots during public discourse. We discuss the implications for designing opinionated chatbots to promote more constructive and less polarized online discussions.

Alleviating Linguistic and Interactional Anxiety of Non-Native Speakers in Multilingual Communication
Peinuan Qin, Justin Peng, Zhengtao Xu, Jiting Cheng, Zicheng Zhu, Naomi Yamashita, Yi-Chieh Lee
ACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW 26)
Non-native speakers (NNSs) frequently encounter speaking difficulties in multilingual communication, where existing approaches have shown promise in facilitating NNSs' comprehension and participation in real-time communication. However, they often overlook providing direct speaking support, where anxiety stemming from linguistic inadequacy and uncertain communication dynamics are core issues. To address this, we introduce an AI tool with translation for real-time speaking support. It also builds a channel for mutual understanding with native speakers (NSs) to mitigate interactional anxiety. Through a within-subjects experiment involving 25 NNS-NS pairs (N = 50) on collaborative tasks, our findings suggest that the tool improved NNSs' speaking self-efficacy, reduced their interactional anxiety, and decreased their workload, particularly for NNSs with below-average language proficiency. Furthermore, NNSs reported a significant sense of support from their NS partners via the mutual understanding channel, and NSs also clearly perceived the NNSs' need for assistance and displayed a strong sense of communicative responsibility. This research underscores the potential of AI support in real-time NNS communication and the importance of promoting mutual understanding, culminating in actionable design insights for future work.
Alleviating Linguistic and Interactional Anxiety of Non-Native Speakers in Multilingual Communication
Peinuan Qin, Justin Peng, Zhengtao Xu, Jiting Cheng, Zicheng Zhu, Naomi Yamashita, Yi-Chieh Lee
ACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW 26)
Non-native speakers (NNSs) frequently encounter speaking difficulties in multilingual communication, where existing approaches have shown promise in facilitating NNSs' comprehension and participation in real-time communication. However, they often overlook providing direct speaking support, where anxiety stemming from linguistic inadequacy and uncertain communication dynamics are core issues. To address this, we introduce an AI tool with translation for real-time speaking support. It also builds a channel for mutual understanding with native speakers (NSs) to mitigate interactional anxiety. Through a within-subjects experiment involving 25 NNS-NS pairs (N = 50) on collaborative tasks, our findings suggest that the tool improved NNSs' speaking self-efficacy, reduced their interactional anxiety, and decreased their workload, particularly for NNSs with below-average language proficiency. Furthermore, NNSs reported a significant sense of support from their NS partners via the mutual understanding channel, and NSs also clearly perceived the NNSs' need for assistance and displayed a strong sense of communicative responsibility. This research underscores the potential of AI support in real-time NNS communication and the importance of promoting mutual understanding, culminating in actionable design insights for future work.
InterPilot: Exploring the Design Space of AI-assisted Job Interview Support for HR Professionals
Zhengtao Xu, Zimo Xia, Zicheng Zhu, Nattapat Boonprakong, Yu-An Chen, Rabih Zbib, Casimiro Pio Carrino, Yi-Chieh Lee
Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA 26)
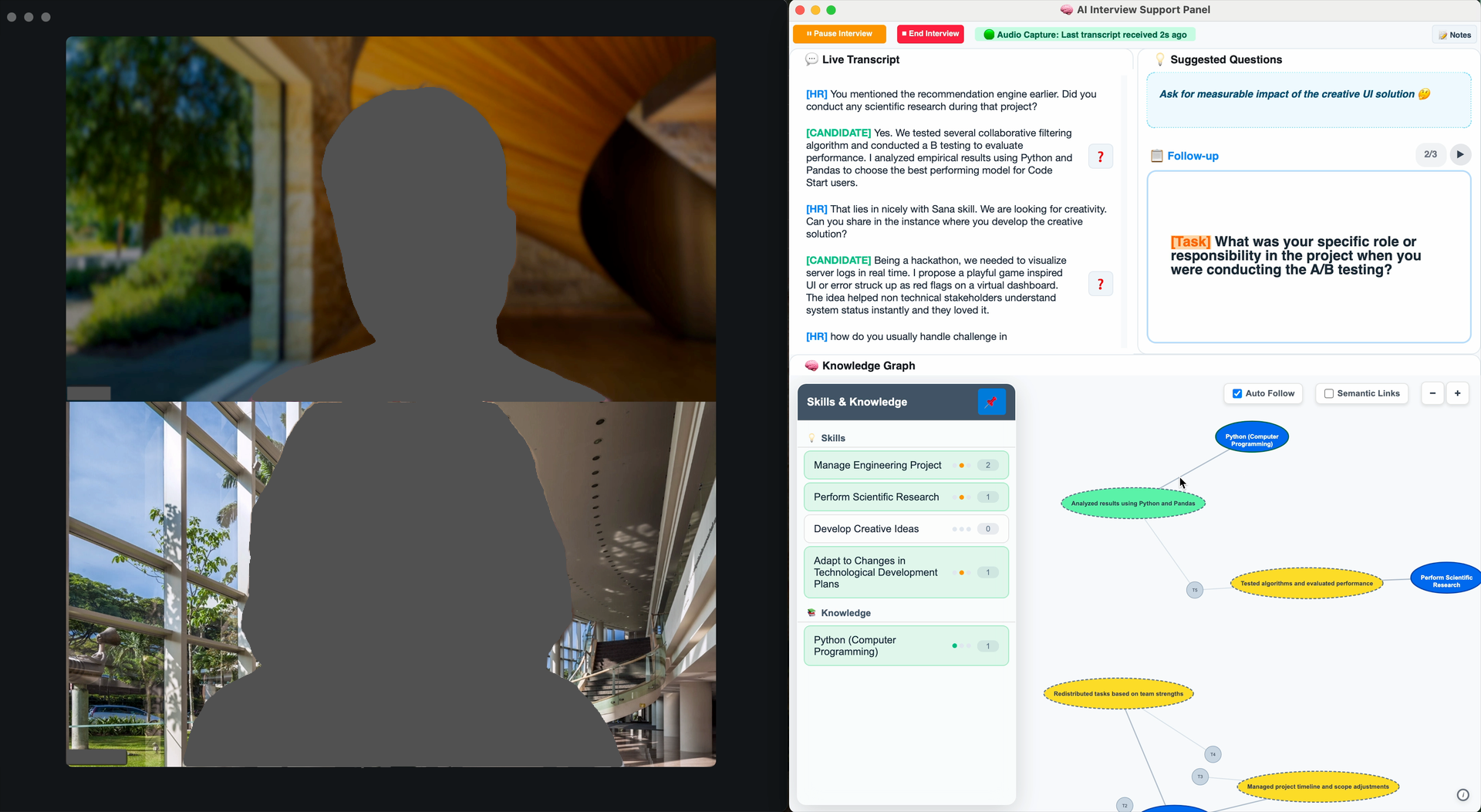
Recruitment interviews are cognitively demanding interactions in which interviewers must simultaneously listen, evaluate candidates, take notes, and formulate follow-up questions. To better understand these challenges, we conducted a formative study with eight HR professionals, from which we derived key design goals for real-time AI support. Guided by these insights, we developed InterPilot, a prototype system that augments interviews through intelligent note-taking and post-interview summary, adaptive question generation, and real-time skill–evidence mapping. We evaluated the system with another seven HR professionals in mock interviews using a within-subjects design. Results show that InterPilot reduced documentation burden without increasing overall workload, but introduced usability trade-offs related to visual attention and interaction complexity. Qualitative findings further reveal tensions around trust and verification when AI suggests highly specific technical questions. We discuss implications for designing future real-time human–AI collaboration in professional settings, highlighting the need to balance assistance granularity, attentional demands, and human agency.
InterPilot: Exploring the Design Space of AI-assisted Job Interview Support for HR Professionals
Zhengtao Xu, Zimo Xia, Zicheng Zhu, Nattapat Boonprakong, Yu-An Chen, Rabih Zbib, Casimiro Pio Carrino, Yi-Chieh Lee
Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA 26)
Recruitment interviews are cognitively demanding interactions in which interviewers must simultaneously listen, evaluate candidates, take notes, and formulate follow-up questions. To better understand these challenges, we conducted a formative study with eight HR professionals, from which we derived key design goals for real-time AI support. Guided by these insights, we developed InterPilot, a prototype system that augments interviews through intelligent note-taking and post-interview summary, adaptive question generation, and real-time skill–evidence mapping. We evaluated the system with another seven HR professionals in mock interviews using a within-subjects design. Results show that InterPilot reduced documentation burden without increasing overall workload, but introduced usability trade-offs related to visual attention and interaction complexity. Qualitative findings further reveal tensions around trust and verification when AI suggests highly specific technical questions. We discuss implications for designing future real-time human–AI collaboration in professional settings, highlighting the need to balance assistance granularity, attentional demands, and human agency.

Who You Explain To Matters: Learning by Explaining to Conversational Agents with Different Pedagogical Roles
Zhengtao Xu, Junti Zhang, Anthony Tang, Yi-Chieh Lee
ACM CHI conference on Human Factors in Computing Systems (CHI 26) 🏅 Honourable Mention
Conversational agents are increasingly used in education for learning support. An application is "learning by explaining", where learners explain their understanding to an agent. However, existing research focuses on single roles, leaving it unclear how different pedagogical roles influence learners' interaction patterns, learning outcomes and experiences. We conducted a between-subjects study (N=96) comparing agents with three pedagogical roles (Tutee, Peer, Challenger) and a control condition while learning an economics concept. We found that different pedagogical roles shaped learning dynamics, including interaction patterns and experiences. Specifically, the Tutee agent elicited the most cognitive investment but led to high pressure. The Peer agent fostered high absorption and interest through collaborative dialogue. The Challenger agent promoted cognitive and metacognitive acts, enhancing critical thinking with moderate pressure. The findings highlight how agent roles shape different learning dynamics, guiding the design of educational agents tailored to specific pedagogical goals and learning phases.
Who You Explain To Matters: Learning by Explaining to Conversational Agents with Different Pedagogical Roles
Zhengtao Xu, Junti Zhang, Anthony Tang, Yi-Chieh Lee
ACM CHI conference on Human Factors in Computing Systems (CHI 26) 🏅 Honourable Mention
Conversational agents are increasingly used in education for learning support. An application is "learning by explaining", where learners explain their understanding to an agent. However, existing research focuses on single roles, leaving it unclear how different pedagogical roles influence learners' interaction patterns, learning outcomes and experiences. We conducted a between-subjects study (N=96) comparing agents with three pedagogical roles (Tutee, Peer, Challenger) and a control condition while learning an economics concept. We found that different pedagogical roles shaped learning dynamics, including interaction patterns and experiences. Specifically, the Tutee agent elicited the most cognitive investment but led to high pressure. The Peer agent fostered high absorption and interest through collaborative dialogue. The Challenger agent promoted cognitive and metacognitive acts, enhancing critical thinking with moderate pressure. The findings highlight how agent roles shape different learning dynamics, guiding the design of educational agents tailored to specific pedagogical goals and learning phases.
2025
Confronting Verbalized Uncertainty: Understanding How LLM’s Verbalized Uncertainty Influences Users in AI-Assisted Decision-Making
Zhengtao Xu, Tianqi Song, Yi-Chieh Lee
International Journal of Human-Computer Studies (IJHCS)
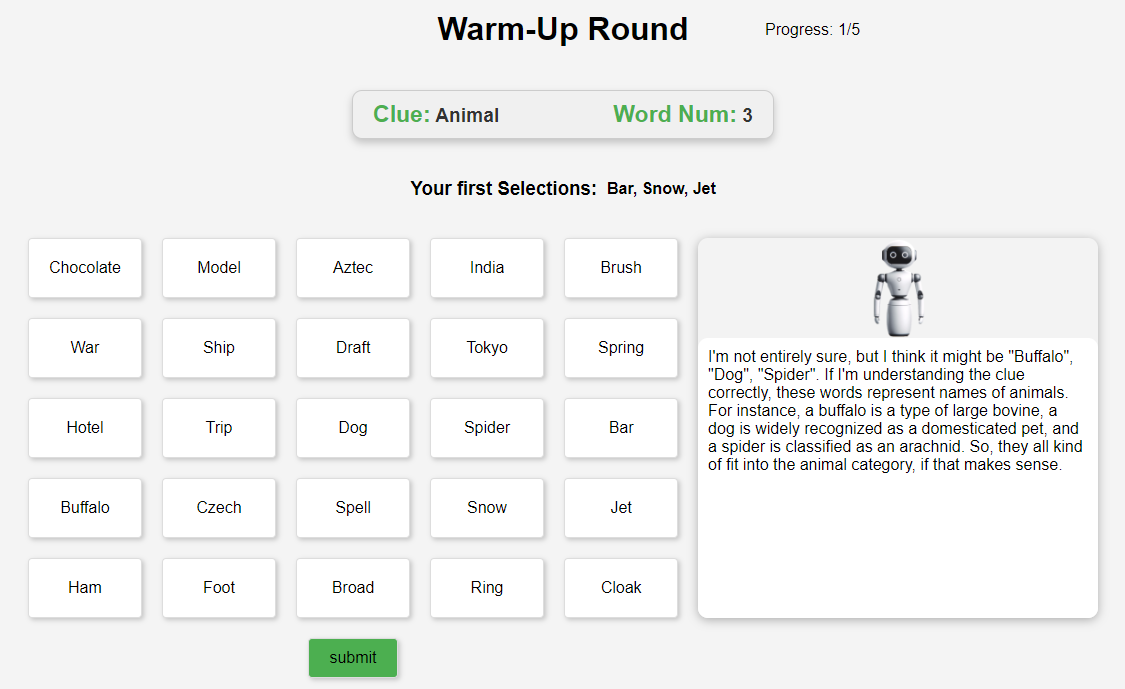
Due to the human-like nature, large language models (LLMs) often express uncertainty in their outputs. This expression, known as "verbalized uncertainty", can appear in phrases such as "I'm sure that [...]" or "It could be [...]". However, few studies have explored how this expression impacts human users' feelings towards AI, including their trust, satisfaction and task performance. Our research aims to fill this gap by exploring how different levels of verbalized uncertainty from the LLM's outputs affect users' perceptions and behaviors in AI-assisted decision-making scenarios. To this end, we conducted a between-condition study (N = 156), dividing participants into six groups based on two accuracy conditions and three conditions of verbalized uncertainty. We also used the widely played word guessing game Codenames to simulate the role of LLMs in assisting human decision-making. Our results show that medium verbalized uncertainty in the LLM's expressions consistently leads to higher user trust, satisfaction, and task performance compared to high and low verbalized uncertainty. Our results also show that participants experience verbalized uncertainty differently based on the accuracy of the LLM. This study offers important implications for the future design of LLMs, suggesting adaptive strategies to express verbalized uncertainty based on the LLM's accuracy.
Confronting Verbalized Uncertainty: Understanding How LLM’s Verbalized Uncertainty Influences Users in AI-Assisted Decision-Making
Zhengtao Xu, Tianqi Song, Yi-Chieh Lee
International Journal of Human-Computer Studies (IJHCS)
Due to the human-like nature, large language models (LLMs) often express uncertainty in their outputs. This expression, known as "verbalized uncertainty", can appear in phrases such as "I'm sure that [...]" or "It could be [...]". However, few studies have explored how this expression impacts human users' feelings towards AI, including their trust, satisfaction and task performance. Our research aims to fill this gap by exploring how different levels of verbalized uncertainty from the LLM's outputs affect users' perceptions and behaviors in AI-assisted decision-making scenarios. To this end, we conducted a between-condition study (N = 156), dividing participants into six groups based on two accuracy conditions and three conditions of verbalized uncertainty. We also used the widely played word guessing game Codenames to simulate the role of LLMs in assisting human decision-making. Our results show that medium verbalized uncertainty in the LLM's expressions consistently leads to higher user trust, satisfaction, and task performance compared to high and low verbalized uncertainty. Our results also show that participants experience verbalized uncertainty differently based on the accuracy of the LLM. This study offers important implications for the future design of LLMs, suggesting adaptive strategies to express verbalized uncertainty based on the LLM's accuracy.
2024
Understanding the Effects of Miscalibrated AI Confidence on User Trust, Reliance, and Decision Efficacy
Jingshu Li, Yitian Yang, Renwen Zhang, Q Vera Liao, Tianqi Song, Zhengtao Xu, Yi-Chieh Lee
arXiv preprint arXiv:2402.07632
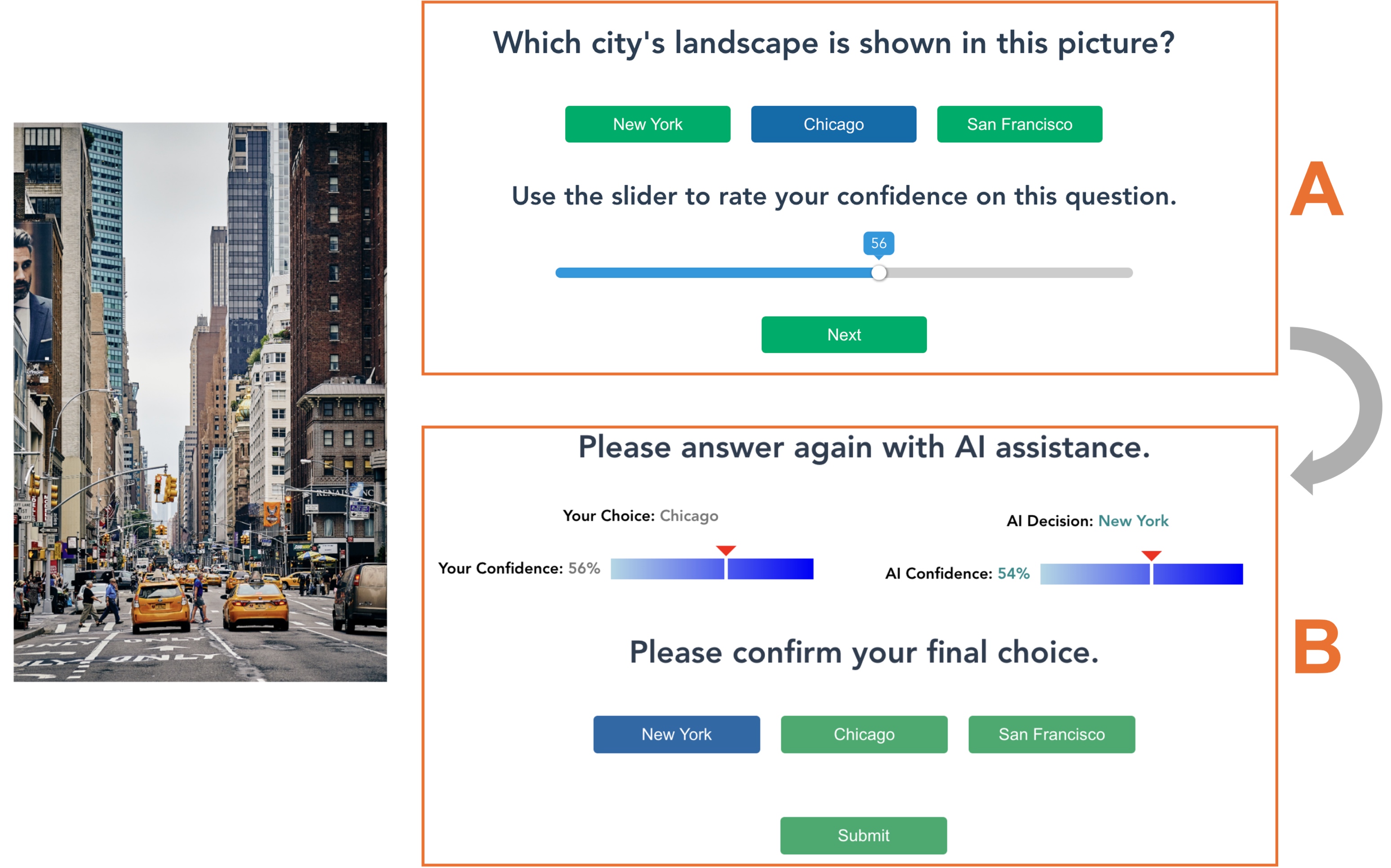
Providing well-calibrated AI confidence can help promote users’ appropriate trust in and reliance on AI, which are essential for AI-assisted decision-making. However, calibrating AI confidence—providing confidence score that accurately reflects the true likelihood of AI being correct—is known to be challenging. To understand the effects of AI confidence miscalibration, we conducted our first experiment. The results indicate that miscalibrated AI confidence impairs users’ appropriate reliance and reduces AI-assisted decision-making efficacy, and AI miscalibration is difficult for users to detect. Then, in our second experiment, we examined whether communicating AI confidence calibration levels could mitigate the above issues. We find that it helps users to detect AI miscalibration. Nevertheless, since such communication decreases users’ trust in uncalibrated AI, leading to high under-reliance, it does not improve the decision efficacy. We discuss design implications based on these findings and future directions to address risks and ethical concerns associated with AI miscalibration.
Understanding the Effects of Miscalibrated AI Confidence on User Trust, Reliance, and Decision Efficacy
Jingshu Li, Yitian Yang, Renwen Zhang, Q Vera Liao, Tianqi Song, Zhengtao Xu, Yi-Chieh Lee
arXiv preprint arXiv:2402.07632
Providing well-calibrated AI confidence can help promote users’ appropriate trust in and reliance on AI, which are essential for AI-assisted decision-making. However, calibrating AI confidence—providing confidence score that accurately reflects the true likelihood of AI being correct—is known to be challenging. To understand the effects of AI confidence miscalibration, we conducted our first experiment. The results indicate that miscalibrated AI confidence impairs users’ appropriate reliance and reduces AI-assisted decision-making efficacy, and AI miscalibration is difficult for users to detect. Then, in our second experiment, we examined whether communicating AI confidence calibration levels could mitigate the above issues. We find that it helps users to detect AI miscalibration. Nevertheless, since such communication decreases users’ trust in uncalibrated AI, leading to high under-reliance, it does not improve the decision efficacy. We discuss design implications based on these findings and future directions to address risks and ethical concerns associated with AI miscalibration.